Глибше занурення у зчитування крос-L2 для гаманців та інших випадків використання
Особлива подяка Йоаву Вайсу, Дену Фінлею, Мартіну Коппельману та командам Arbitrum, Optimism, Polygon, Scroll і SoulWallet за відгуки та рецензії.
У цій статті про три переходи я виклав деякі ключові причини, чому важливо почати думати про підтримку L1 + крос-L2, безпеку гаманців і конфіденційність як про необхідні базові функції стека екосистеми, замість того, щоб створювати кожну з цих речей як доповнення, які можуть бути розроблені окремими гаманцями окремо.
Ця публікація буде присвячена технічним аспектам однієї конкретної підпроблеми: як полегшити читання L1 з L2, L2 з L1 або одного L2 з іншого L2. Вирішення цієї проблеми має вирішальне значення для реалізації архітектури розділення активів і сховищ ключів, але вона також має цінні варіанти використання в інших сферах, зокрема для оптимізації надійних крос-L2 викликів, включаючи такі випадки використання, як переміщення активів між L1 і L2.
Рекомендована література для попереднього читання
- Пост про три переходи
- Ідеї від команди Safe щодо володіння активами в декількох ланцюгах
- Чому нам потрібне широке впровадження гаманців соціального відновлення
- ZK-SNARKs та деякі програми для захисту приватності
- Данкрад про зобов'язання Казахстану
- Вербові дерева
Зміст
- Яка мета?
- Як виглядає підтвердження перехресного ланцюга?
- Які схеми доведення ми можемо використовувати?
- Як L2 дізнається корінь останнього стану Ethereum?
- Гаманці на ланцюжках, які не є L2
- Збереження конфіденційності
- Зведення
Яка мета?
Як тільки L2 стануть більш поширеними, користувачі матимуть активи на декількох L2, а можливо, і на L1. Як тільки гаманці смарт-контрактів (multisig, соціальне відновлення або інші) стануть масовими, ключі, необхідні для доступу до певних облікових записів, з часом зміняться, і старі ключі більше не будуть дійсними. Як тільки обидві ці речі трапляються, користувачеві потрібно мати можливість змінити ключі, які мають право доступу до багатьох облікових записів, що знаходяться в різних місцях, не здійснюючи при цьому надзвичайно великої кількості транзакцій.
Зокрема, нам потрібен спосіб роботи з контрфактичними адресами: адресами, які ще не були "зареєстровані" в ланцюжку, але які, тим не менш, повинні отримувати та безпечно зберігати кошти. Ми всі залежимо від контрфактичних адрес: коли ви вперше використовуєте Ethereum, ви можете згенерувати адресу ETH, яку хтось може використати, щоб заплатити вам, без "реєстрації" адреси в ланцюжку (що вимагало б сплати txfee, а отже, вже мати певну кількість ETH).
В EOA всі адреси починаються з контрфактичних адрес. З гаманцями смарт-контрактів контрфактичні адреси все ще можливі, багато в чому завдяки CREATE2, який дозволяє вам мати адресу ETH, яка може бути заповнена тільки смарт-контрактом, що має код, який відповідає певному хешу.

Алгоритм обчислення адреси EIP-1014 (CREATE2 ).
Однак гаманці смарт-контрактів створюють нову проблему: можливість зміни ключів доступу. Адреса, яка є хешем initcode, може містити лише початковий ключ верифікації гаманця. Поточний ключ верифікації буде зберігатися в сховищі гаманця, але цей запис не поширюється магічним чином на інші L2.
Якщо користувач має багато адрес на багатьох L2, включаючи адреси, про які (оскільки вони є контрфактичними) L2, на якому він перебуває, не знає, то, схоже, існує лише один спосіб дозволити користувачам змінювати свої ключі: архітектура розділення активів/сховища ключів. Кожен користувач має (i) "контракт на зберігання ключів" (на L1 або на одному конкретному L2), який зберігає ключ верифікації для всіх гаманців разом з правилами зміни ключа, і (ii) "контракти на гаманці" на L1 і багатьох L2, які зчитують перехресний ланцюжок для отримання ключа верифікації.

Існує два способи реалізації цього:
- Полегшена версія (перевірка тільки для оновлення ключів): кожен гаманець зберігає ключ верифікації локально і містить функцію, яку можна викликати для перевірки крос-ланцюгового підтвердження поточного стану сховища ключів і оновлення свого локально збереженого ключа верифікації для відповідності. Коли гаманець використовується вперше на певному L2, виклик цієї функції для отримання поточного ключа верифікації зі сховища ключів є обов'язковим.
- Перевага: економно використовує перехресні перевірки, тому не страшно, якщо перехресні перевірки коштують дорого. Всі кошти можна витрачати лише з поточними ключами, тому це все ще безпечно.
- Недолік: Щоб змінити ключ верифікації, вам доведеться змінити ключ на ланцюжку і в сховищі ключів, і в кожному гаманці, який вже ініціалізовано (але не в контрфактичних гаманцях). Це може коштувати багато бензину.
- Важкий варіант (перевірка для кожного tx): для кожної транзакції необхідне підтвердження крос-ланцюга, що показує ключ, який знаходиться в сховищі ключів.
- Плюси: менша системна складність і дешеве оновлення сховища ключів.
- Недолік: дорогий per-tx, тому вимагає набагато більшої інженерії, щоб зробити крос-ланцюгові докази прийнятно дешевими. Також нелегко сумісний з ERC-4337, який наразі не підтримує зчитування мутабельних об'єктів під час валідації в перехресних контрактах.
Як виглядає підтвердження перехресного ланцюга?
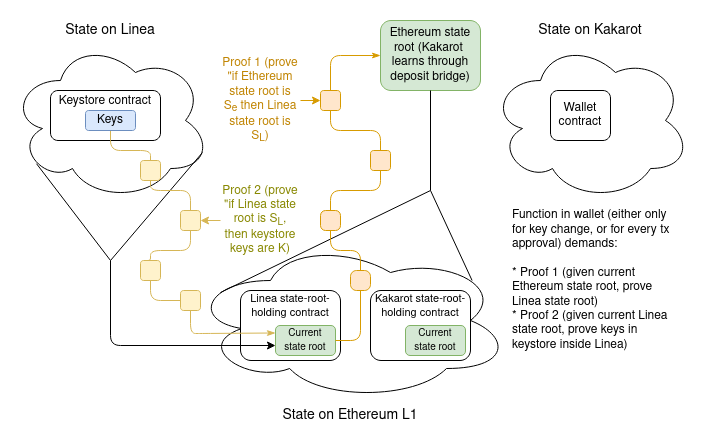
Щоб показати всю складність, ми розглянемо найскладніший випадок: коли сховище ключів знаходиться на одному L2, а гаманець - на іншому L2. Якщо або сховище ключів, або гаманець знаходяться на L1, то потрібна лише половина цього дизайну.

Припустимо, що сховище ключів знаходиться на Linea, а гаманець - на Kakarot. Повний доказ того, що ключі від гаманця складаються з:
- Доведення, що підтверджує поточний корінь стану Linea, враховуючи поточний корінь стану Ethereum, про який знає Kakarot
- Доведення, яке доводить наявність поточних ключів у сховищі за поточним коренем стану Linea
Тут є два основних складних питання реалізації:
- Які докази ми використовуємо? (Це докази Меркла? щось інше?)
- Як L2 дізнається корінь останнього стану L1 (Ethereum) (або, як ми побачимо, потенційно повний стан L1) в першу чергу? І навпаки, як L1 дізнається корінь стану L2?
- В обох випадках, як довго триває затримка між тим, що відбувається з одного боку, і тим, що це можна довести іншій стороні?
Які схеми доведення ми можемо використовувати?
Є п'ять основних варіантів:
- Докази Меркла
- ЗК-СНАРК загального призначення
- Доведення спеціального призначення (напр. з тенге)
- Докази Verkle, які знаходяться десь між KZG і ZK-SNARK як за навантаженням на інфраструктуру, так і за вартістю.
- Немає доказів і покладатися на прямі свідчення держави
З точки зору необхідної інфраструктурної роботи та вартості для користувачів, я ранжую їх приблизно наступним чином:
"Агрегація" - це ідея об'єднання всіх доказів, наданих користувачами в кожному блоці, у велике мета-доказ, який об'єднує їх усі. Це можливо для SNARK, і для KZG, але не для гілок Меркла (ви можете трохи об'єднати гілки Меркла, але це лише заощадить вам log(txs на блок) / log(загальна кількість сховищ ключів), можливо, 15-30% на практиці, так що це, ймовірно, не варте витрат).
Агрегація має сенс лише тоді, коли схема має значну кількість користувачів, тож у версії 1 можна не використовувати агрегацію, а реалізувати її у версії 2.
Як працює перевірка Merkle?
Тут все просто: просто дотримуйтесь схеми, наведеної в попередньому розділі. Точніше, кожне "доведення" (припускаючи випадок максимальної складності доведення одного L2 до іншого L2) буде містити:
- Гілка Меркла, що доводить наявність кореня стану у L2-власника сховища ключів, враховуючи найсвіжіший корінь стану Ethereum, про який L2 знає. Корінь стану L2, що зберігає ключі, зберігається у відомому слоті пам'яті за відомою адресою (контракт на L1, що представляє L2), і тому шлях по дереву може бути жорстко закодований.
- Гілка Меркла, яка доводить поточні ключі верифікації, враховуючи корінь стану сховища ключів L2. Знову ж таки, ключ верифікації зберігається у відомому слоті пам'яті за відомою адресою, тому шлях може бути жорстко закодований.
На жаль, докази стану Ethereum складні, але існують бібліотеки для їх перевірки, і якщо ви використовуєте ці бібліотеки, то цей механізм не надто складно реалізувати.
Більшою проблемою є вартість. Доведення за методом Меркла довгі, а дерева Патриції, на жаль, в ~3.9 разів довші, ніж потрібно (саме: ідеальне доведення за методом Меркла для дерева, що містить N об'єктів, має довжину 32 log2(N) байти, а оскільки дерева Патриції в Ethereum мають по 16 листків на дитину, доведення для цих дерев мають довжину 32 15 log16(N) ~= 125 log2(N) байти). У державі з приблизно 250 мільйонами (~2²⁸) акаунтів це означає, що кожне доведення займає 125 * 28 = 3500 байт, або близько 56 000 газів, плюс додаткові витрати на розшифровку і перевірку хешів.
Два підтвердження разом коштуватимуть від 100 000 до 150 000 кубометрів газу (не враховуючи перевірку підпису, якщо вона використовується для кожної транзакції) - значно більше, ніж нинішня базова ціна 21 000 кубометрів газу за транзакцію. Але невідповідність погіршується, якщо доказ перевіряється на L2. Обчислення всередині L2 є дешевими, оскільки вони виконуються поза ланцюжком і в екосистемі з набагато меншою кількістю вузлів, ніж L1. З іншого боку, дані повинні бути розміщені в L1. Отже, порівняння не 21000 газу проти 150 000 газу, а 21 000 L2 газу проти 100 000 L1 газу.
Ми можемо підрахувати, що це означає, порівнюючи витрати на газ L1 та L2:
Наразі L1 приблизно в 15-25 разів дорожчий за L2 для простих відправлень і в 20-50 разів дорожчий для обміну токенів. Прості відправки відносно об'ємні за обсягом даних, але свопи набагато важчі для обчислень. Таким чином, свопи є кращим орієнтиром для оцінки вартості обчислень L1 та L2. Беручи все це до уваги, якщо ми припустимо 30-кратне співвідношення між вартістю обчислень на L1 і L2, це означає, що доведення тесту Меркла на L2 буде коштувати еквівалентно, можливо, п'ятдесяти звичайним транзакціям.
Звичайно, використання бінарного дерева Меркла може скоротити витрати в ~4 рази, але навіть при цьому вартість в більшості випадків буде занадто високою - і якщо ми готові пожертвувати несумісністю з поточним гексаріальним деревом станів Ethereum, ми можемо шукати ще кращі варіанти.
Як працюватиме коректура ZK-SNARK?
Концептуально, використання ZK-SNARK також легко зрозуміти: ви просто замінюєте доведення Меркла на схемі вище на ZK-SNARK, який доводить, що ці доведення Меркла існують. ZK-SNARK коштує ~400,000 газу для обчислень і близько 400 байт (порівняйте: 21 000 газу і 100 байт для базової транзакції, яка в майбутньому може бути зменшена до ~25 байт завдяки стисненню). Отже, з точки зору обчислень, ZK-SNARK коштує в 19 разів більше, ніж базова транзакція сьогодні, а з точки зору даних, ZK-SNARK коштує в 4 рази більше, ніж базова транзакція сьогодні, і в 16 разів більше, ніж базова транзакція може коштувати в майбутньому.
{kind=link}
Ці числа є значним покращенням порівняно з доказами Меркла, але вони все ще досить дорогі. Є два способи покращити це: (i) спеціальні доведення KZG, або (ii) агрегація, подібна до агрегації ERC-4337, але з використанням більш хитромудрої математики. Ми можемо розглянути обидва варіанти.
Як працюватимуть спеціальні перевірки KZG?
Увага, в цьому розділі набагато більше математики, ніж в інших розділах. Це тому, що ми виходимо за рамки інструментів загального призначення і створюємо щось спеціальне, щоб бути дешевшим, тому нам доводиться набагато більше заглиблюватися "під капот". Якщо ви не любите глибоку математику, переходьте до наступного розділу.
По-перше, нагадаємо, як працюють зобов'язання тенге:
- Ми можемо представити набір даних [D_1 ... D_n] за допомогою КЗГ-доведення многочлена, отриманого з цих даних: зокрема, многочлена P, де P(w) = D_1, P(w²) = D_2 ... P(wⁿ) = D_n. w - "корінь з одиниці", значення, де wᴺ = 1 для деякої області оцінювання розміром N (все це робиться у скінченному полі).
- Щоб "прив'язатися" до P, ми створюємо точку еліптичної кривої com(P) = P₀ G + P₁ S₁ + ... + Pₖ * Sₖ. Ось:
- G - точка генератора кривої
- Pᵢ - коефіцієнт i-го степеня полінома P
- Sᵢ - це i-а точка в довіреному налаштуванні
- Щоб довести, що P(z) = a, ми створимо многочлен Q = (P - a) / (X - z), і створимо для нього обмеження com(Q). Створити такий многочлен можливо лише у тому випадку, якщо P(z) дійсно дорівнює a.
- Щоб перевірити доведення, перевіримо рівняння Q * (X - z) = P - a за допомогою перевірки еліптичної кривої на доведення com(Q) та полінома com(P): перевіримо e(com(Q), com(X - z)) ?= e(com(P) - com(a), com(1))
Деякі ключові властивості, які важливо розуміти, є наступними:
- Доказом є лише значення com(Q), яке дорівнює 48 байтам
- com(P₁) + com(P₂) = com(P₁ + P₂)
- Це також означає, що ви можете "редагувати" значення в існуючому зобов'язанні. Припустимо, що ми знаємо, що D_i наразі дорівнює a, ми хочемо встановити його на b, а існуюче зобов'язання на D дорівнює com(P). Зобов'язання "P, але з P(wⁱ) = b, і жодні інші оцінки не змінилися", тоді ми встановлюємо com(new_P) = com(P) + (b-a) * com(Lᵢ), де Lᵢ - це "поліном Лагранжа", який дорівнює 1 у точці wⁱ і 0 в інших точках wʲ.
- Для ефективного виконання цих оновлень всі N зобов'язань по поліномам Лагранжа (com(Lᵢ)) можуть бути попередньо обчислені і збережені кожним клієнтом. Усередині контракту в ланцюжку може бути занадто складно зберігати всі N зобов'язань, тому замість цього ви можете створити KZG-зобов'язання для набору значень com(L_i) (або hash(com(L_i)), так що коли комусь знадобиться оновити дерево в ланцюжку, вони можуть просто надати відповідне com(L_i) з доказом його правильності.
Таким чином, ми маємо структуру, де ми можемо просто продовжувати додавати значення в кінець постійно зростаючого списку, хоча і з певним обмеженням розміру (в реальності, сотні мільйонів можуть бути життєздатними). Потім ми використовуємо цю структуру даних для управління (i) зобов'язаннями щодо списку ключів на кожному L2, які зберігаються на цьому L2 і відображаються на L1, і (ii) зобов'язаннями щодо списку ключових зобов'язань L2, які зберігаються на Ethereum L1 і відображаються на кожному L2.
Оновлення зобов'язань може або стати частиною основної логіки L2, або може бути реалізовано без змін в основному протоколі L2 за допомогою мостів внесення та вилучення зобов'язань.

Таким чином, потрібен повний доказ:
- Останній com(список ключів) на сховищі ключів L2 (48 байт)
- KZG доказ того, що com(key list) є значенням всередині com(mirror_list), прихильність до списку всіх прихильностей списку ключів (48 байт)
- KZG підтвердження вашого ключа в com(key list) (48 байт, плюс 4 байти для індексу)
Насправді можна об'єднати дві перевірки KZG в одну, так що ми отримаємо загальний розмір всього 100 байт.
Зверніть увагу на одну тонкість: оскільки список ключів є списком, а не картою ключ/значення, як у випадку зі станом, у списку ключів доведеться призначати позиції послідовно. Договір про зобов'язання щодо ключів міститиме власний внутрішній реєстр, який відображатиме кожне сховище ключів на ідентифікатор, і для кожного ключа зберігатиме хеш (ключ, адреса сховища), а не просто ключ, щоб однозначно повідомляти іншим L2, про яке саме сховище ключів йдеться в конкретному записі.
Перевагою цієї техніки є те, що вона дуже добре працює на L2. Дані складають 100 байт, що приблизно в 4 рази коротше, ніж ZK-SNARK і набагато коротше, ніж доказ Меркла. Вартість обчислень в основному дорівнює одній перевірці пар розміру 2, або приблизно 119 000 газів. На L1 дані менш важливі, ніж обчислення, і тому, на жаль, KZG є дещо дорожчим за доведення Меркла.
Як працюватимуть дерева Веркле?
Дерева Веркле по суті включають в себе накладання KZG-зобов'язань (або IPA-зобов'язань, які можуть бути більш ефективними і використовувати простішу криптографію) одне на одне: для зберігання 2⁴⁸ значень, ви можете зробити KZG-зобов'язання на список з 2²⁴ значень, кожне з яких саме по собі є KZG-зобов'язанням на 2²⁴ значень. Вербові дерева сильно <a href="https://notes.ethereum.org/@vbuterin/verkle_tree_eip"> розглянуто для дерева станів Ethereum, оскільки дерева Verkle можна використовувати для зберігання карт ключ-значення, а не тільки списків (в принципі, ви можете створити дерево розміром 2²⁵⁶, але почати його порожнім, заповнюючи певні частини дерева лише тоді, коли вам дійсно потрібно їх заповнити).

Як виглядає дерево Веркле. На практиці ви можете надати кожному вузлу ширину 256 == 2⁸ для дерев на основі IPA або 2²⁴ для дерев на основі KZG.
Докази у деревах Verkle дещо довші, ніж у KZG; вони можуть мати довжину у кілька сотень байт. Їх також важко перевірити, особливо якщо ви намагаєтеся об'єднати багато доказів в один.
Реально дерева Веркле слід розглядати як дерева Меркла, але більш життєздатні без SNARKing (через меншу вартість даних), і дешевші з SNARKing (через меншу вартість верифікатора).
Найбільшою перевагою дерев Веркле є можливість узгодження структур даних: Доведення Verkle можна використовувати безпосередньо над станом L1 або L2, без накладання структур, використовуючи той самий механізм для L1 і L2. Коли квантові комп'ютери стануть проблемою, або коли доведення гілок Меркла стане достатньо ефективним, дерева Веркле можна буде замінити на бінарні хеш-дерева з відповідною хеш-функцією, дружньою до SNARK.
Агрегація
Якщо N користувачів роблять N транзакцій (або, що більш реалістично, N ERC-4337 UserOperations), які повинні довести N міжланцюгових тверджень, ми можемо заощадити багато газу, об'єднавши ці докази: конструктор, який об'єднує ці транзакції в блок або пакет, який йде в блок, може створити єдиний доказ, який доводить всі ці твердження одночасно.
Це може означати:
- Доведення ZK-SNARK для N-мерклівських гілок
- Мультизахист KZG
- Мультизахист Verkle (або ZK-SNARK мультизахисту)
У всіх трьох випадках докази коштували б лише кілька сотень тисяч газу кожна. Розробнику потрібно буде створити по одному такому блоку на кожному L2 для користувачів цього L2; отже, для того, щоб це було корисно для побудови, схема в цілому повинна мати достатній рівень використання, оскільки дуже часто існує принаймні кілька транзакцій в межах одного блоку на декількох основних L2.
Якщо використовуються ZK-SNARK, то основними граничними витратами є просто "бізнес-логіка" передачі номерів між контрактами, тобто, можливо, кілька тисяч L2 газу на користувача. Якщо використовуються мультидокази KZG, то для кожного сховища ключів L2, яке використовується в цьому блоці, потрібно буде додати 48 газів, тому гранична вартість схеми на одного користувача додасть ще ~800 газів L1 на L2 (не на користувача) зверху. Але ці витрати набагато нижчі, ніж витрати без агрегації, які неминуче включають понад 10 000 газу L1 і сотні тисяч газу L2 на кожного користувача. Для дерев Verkle ви можете або використовувати мультидокази Verkle безпосередньо, додаючи близько 100-200 байт на користувача, або ви можете зробити ZK-SNARK з мультидоказу Verkle, який має аналогічну вартість, що і ZK-SNARK гілок Merkle, але значно дешевший у доведенні.
З точки зору реалізації, ймовірно, найкраще, щоб бандери агрегували міжланцюгові докази за допомогою стандарту абстракції облікових записів ERC-4337. ERC-4337 вже має механізм для збирачів, який дозволяє об'єднувати частини UserOperations у користувацькі способи. Існує навіть <a href="https://hackmd.io/@voltrevo/BJ0QBy3zi"> реалізація цього для агрегації сигнатур BLS, що може знизити витрати газу на L2 в 1,5-3 рази залежно від того, які інші форми стиснення включені.

Діаграма з <a href="https://hackmd.io/@voltrevo/BJ0QBy3zi"> пост про реалізацію гаманця BLS, що демонструє робочий процес агрегатних підписів BLS в рамках попередньої версії ERC-4337. Робочий процес агрегації перехресних доказів, ймовірно, буде дуже схожим.
Пряме зчитування стану
Останньою можливістю, яка може бути використана лише для L2, що читає L1 (а не L1, що читає L2), є модифікація L2, щоб дозволити їм здійснювати статичні виклики контрактів на L1 напряму.
Це можна зробити за допомогою опкоду або прекомпіляції, яка дозволяє викликати L1, де ви вказуєте адресу призначення, газ і дані виклику, а вона повертає вихідні дані, хоча, оскільки ці виклики є статичними, вони не можуть фактично змінити стан L1. L2 вже має знати про L1, щоб обробляти депозити, тому немає нічого принципового, що заважало б впровадити таку можливість; це, в основному, технічна проблема реалізації (див.: цей RFP від Optimism для підтримки статичних викликів до L1).
Зауважте, що якщо сховище клавіш знаходиться на L1, а L2 інтегрують функціонал статичного виклику L1, то ніяких доказів не потрібно взагалі! Однак, якщо L2 не інтегрує статичні виклики L1, або якщо сховище ключів знаходиться на L2 (що, можливо, з часом доведеться зробити, коли L1 стане занадто дорогим для користувачів, щоб використовувати його хоч трохи), тоді будуть потрібні докази.
Як L2 дізнається корінь останнього стану Ethereum?
Всі наведені вище схеми вимагають від L2 доступу або до кореня останнього стану L1, або до всього останнього стану L1. На щастя, всі L2 вже мають певну функціональність для доступу до нещодавнього стану L1. Це пов'язано з тим, що їм потрібна така функціональність для обробки повідомлень, що надходять з L1 на L2, зокрема депозитів.
І дійсно, якщо L2 має функцію депозиту, то ви можете використовувати цей L2 як є, щоб перемістити корені стану L1 в контракт на L2: просто в контракті на L1 викличте опкод BLOCKHASH і передайте його на L2 як повідомлення про депозит. Повний заголовок блоку можна отримати і витягти корінь його стану на стороні L2. Однак було б набагато краще, якби кожен L2 мав явний спосіб прямого доступу або до повного останнього стану L1, або до коренів останнього стану L1.
Основною проблемою оптимізації способу отримання L2 останніх коренів станів L1 є одночасне досягнення безпеки та низької затримки:
- Якщо L2 реалізує функцію "прямого читання L1" ліниво, читаючи лише фіналізовані корені стану L1, то затримка зазвичай становить 15 хвилин, але в екстремальному випадку витоку неактивності (з яким вам доведеться миритися) затримка може становити кілька тижнів.
- L2 може бути спроектовано так, щоб читати набагато більш пізні корені станів L1, але оскільки L1 може повертатися (навіть при однослотовій фінальності, повернення може відбуватися під час витоку бездіяльності), то L2 також повинен мати можливість повертатися. Це технічно складно з точки зору програмної інженерії, але принаймні Optimism вже має таку можливість.
- Якщо ви використовуєте депозитний міст для перенесення коренів штату L1 в L2, то проста економічна життєздатність може вимагати тривалого часу між оновленнями депозитів: якщо повна вартість депозиту становить 100 000 gas, і ми припускаємо, що ETH коштує $1800, а комісія - 200 gwei, і корені L1 переносяться в L2 один раз в день, це буде коштувати $36 на L2 в день, або $13148 на L2 в рік для підтримки системи. При затримці на одну годину це становить $315 569 за L2 на рік. У кращому випадку, постійний потік нетерплячих заможних користувачів покриває витрати на оновлення і підтримує систему в актуальному стані для всіх інших. У гіршому випадку, якомусь альтруїстичному акторові доведеться заплатити за це самому.
- "Оракули" (принаймні, технологія, яку деякі дефіцитні люди називають "оракулами") тут не є прийнятним рішенням: управління ключами гаманця - це дуже критичний для безпеки низькорівневий функціонал, і тому він повинен залежати щонайбільше від декількох частин дуже простої, криптографічно ненадійної низькорівневої інфраструктури.
Крім того, у зворотному напрямку (L1 читає L2):
- При оптимістичному розгортанні, коріння штату займає один тиждень, щоб досягти L1 через затримку з перевіркою на шахрайство. Наразі на рулонах ZK це займає кілька годин через комбінацію часу вистоювання та економічних обмежень, хоча майбутні технології дозволять скоротити цей час.
- Попередні підтвердження (від секвенаторів, атестаторів тощо) не є прийнятним рішенням для зчитування L1 з L2. Управління гаманцем - це дуже критичний з точки зору безпеки низькорівневий функціонал, тому рівень безпеки зв'язку L2 -> L1 повинен бути абсолютним: не повинно бути навіть можливості проштовхнути фальшивий корінь стану L1, перехопивши набір валідаторів L2. Єдині державні корені, яким повинен довіряти L1, - це державні корені, які були прийняті як остаточні за договором L2 про володіння державним коренем на L1.
Деякі з цих швидкостей для бездовірчих крос-ланцюгових операцій є неприйнятно повільними для багатьох випадків використання дефі; для таких випадків вам дійсно потрібні швидші мости з більш недосконалими моделями безпеки. Однак для випадку оновлення ключів гаманців більш прийнятними є довші затримки: ви не затримуєте транзакції на години, ви затримуєте зміну ключів. Вам просто доведеться довше зберігати старі ключі. Якщо ви змінюєте ключі через те, що їх вкрали, то у вас є значний період вразливості, але його можна зменшити, наприклад, за допомогою гаманців з функцією заморожування.
Зрештою, найкращим рішенням, що мінімізує затримку, є реалізація прямого зчитування коренів стану L1 в оптимальний спосіб, де кожен блок L2 (або журнал обчислення коренів стану) містить вказівник на останній блок L1, тому якщо L1 повертається, то L2 також може повернутися. Контракти в сховищі повинні бути розміщені або в основній мережі, або на L2, які є ZK-розгортаннями і тому можуть швидко зафіксувати на L1.

Блоки ланцюжка L2 можуть мати залежності не тільки від попередніх блоків L2, але й від блоку L1. Якщо L1 повертається повз таке посилання, L2 також повертається. Варто зазначити, що саме так працювала і більш рання (до Данка) версія шардингу; див. код тут.
Наскільки сильний зв'язок з Ethereum потрібен іншому ланцюжку, щоб утримувати гаманці, чиї сховища ключів вкорінені в Ethereum або L2?
На диво, не так вже й багато. Насправді, це навіть не обов'язково має бути роллап: якщо це L3 або валідум, то там можна тримати гаманці, якщо ви тримаєте сховища ключів або на L1, або на ZK роллапі. Що вам дійсно потрібно, так це прямий доступ до коріння Ethereum, а також технічні та соціальні зобов'язання щодо готовності до реорганізації, якщо Ethereum реорганізується, і хардфорку, якщо Ethereum хардфоркує.
Однією з цікавих дослідницьких проблем є визначення того, наскільки можливо, щоб ланцюг мав таку форму з'єднання з кількома іншими ланцюгами (наприклад, з іншими ланцюгами). Ethereum і Zcash). Наївно робити це можливо: ваш ланцюжок може погодитися на реорган, якщо відбудеться реорган Ethereum або Zcash (і хардфорк, якщо відбудеться хардфорк Ethereum або Zcash), але тоді ваші оператори вузлів і ваша спільнота в цілому матимуть подвійну технічну і політичну залежність. Таким чином, така технологія може бути використана для підключення до кількох інших ланцюгів, але з більшими витратами. Схеми на основі ZK мостів мають привабливі технічні характеристики, але у них є ключовий недолік - вони не стійкі до 51% атак або хардфорків. Можливо, є більш розумні рішення.
Збереження конфіденційності
В ідеалі, ми також хочемо зберегти конфіденційність. Якщо у вас багато гаманців, якими керує одне сховище ключів, ми хочемо переконатися в цьому:
- Публічно не відомо, що всі ці гаманці пов'язані між собою.
- Опікуни, які займаються соціальною реабілітацією, не дізнаються, які адреси вони охороняють.
Це створює кілька проблем:
- Ми не можемо використовувати докази Меркла безпосередньо, оскільки вони не зберігають конфіденційність.
- Якщо ми використовуємо KZG або SNARK, то в доказі потрібно надати сліпу версію ключа верифікації, не розкриваючи місцезнаходження ключа верифікації.
- Якщо ми використовуємо агрегацію, то агрегатор не повинен дізнаватися місце розташування у відкритому тексті; скоріше, агрегатор повинен отримувати сліпі докази і мати можливість їх агрегувати.
- Ми не можемо використовувати "полегшену версію" (використовувати крос-ланцюгові докази тільки для оновлення ключів), тому що це створює витік конфіденційності: якщо багато гаманців оновлюються одночасно через процедуру оновлення, час витоку інформації про те, що ці гаманці, ймовірно, пов'язані між собою. Тому нам доводиться використовувати "важку версію" (крос-ланцюгові докази для кожної транзакції).
У випадку з SNARK'ами рішення концептуально просте: докази за замовчуванням приховують інформацію, і агрегатор повинен генерувати рекурсивний SNARK, щоб довести SNARK'и.
Основна проблема цього підходу сьогодні полягає в тому, що агрегація вимагає від агрегатора створення рекурсивного SNARK, який наразі є досить повільним.
З KZG ми можемо використовувати <a href="https://notes.ethereum.org/@vbuterin/non_index_revealing_proof"> це роботу над неіндексованими доказами KZG (див. також: більш формалізовану версію цієї роботи в статті Caulk) як відправну точку. Агрегація сліпих доказів, однак, є відкритою проблемою, яка потребує більшої уваги.
Пряме зчитування L1 зсередини L2, на жаль, не зберігає конфіденційність, хоча реалізація функції прямого зчитування все ще є дуже корисною, як для мінімізації затримок, так і через її корисність для інших додатків.
Зведення
- Для створення міжмережевих гаманців соціального відновлення найбільш реалістичним робочим процесом є гаманець, який підтримує сховище ключів в одному місці, і гаманці в багатьох місцях, де гаманець зчитує сховище ключів або (i) для оновлення свого локального представлення ключа перевірки, або (ii) під час процесу перевірки кожної транзакції.
- Ключовим компонентом, який робить це можливим, є перехресні перевірки ланцюжків. Нам потрібно добряче оптимізувати ці докази. Або ZK-SNARKs, які чекають на перевірку Verkle, або кастомне рішення KZG здаються найкращими варіантами.
- У довгостроковій перспективі для мінімізації витрат знадобляться протоколи агрегації, в яких пакувальники генерують сукупні докази в рамках створення пакета всіх UserOperations, які були надіслані користувачами. Це, ймовірно, має бути інтегровано в екосистему ERC-4337, хоча зміни до ERC-4337, ймовірно, будуть потрібні.
- L2 слід оптимізувати так, щоб мінімізувати затримку читання стану L1 (або принаймні кореня стану) зсередини L2. L2, що безпосередньо зчитує стан L1, є ідеальним варіантом і дозволяє заощадити місце для доказу.
- Гаманці можуть бути не тільки на L2; ви також можете розміщувати гаманці на системах з нижчим рівнем зв'язку з Ethereum (L3, або навіть окремих ланцюжках, які погоджуються включати корені стану Ethereum і реорг або хардфорк тільки тоді, коли Ethereum реоргує або хардфоркує).
- Однак, сховища ключів повинні бути або на L1, або на високозахищеному ZK-сховищі L2. Перебування на рівні L1 значно зменшує складність, хоча в довгостроковій перспективі навіть це може виявитися занадто дорогим, тому виникає потреба у сховищах ключів на рівні L2.
- Збереження конфіденційності вимагатиме додаткової роботи і зробить деякі варіанти складнішими. Однак, ймовірно, нам все одно слід рухатися в бік рішень, що зберігають конфіденційність, і, принаймні, переконатися, що все, що ми пропонуємо, сумісне із збереженням конфіденційності.
Відмова від відповідальності:.
- Ця стаття передрукована з сайту[vitalik], всі авторські права належать первинному автору[Віталіку Бутеріну]. Якщо у вас є заперечення щодо цього передруку, будь ласка, зв'яжіться з командою Gate Learn, і вони оперативно його опрацюють.
- Відмова від відповідальності: Погляди та думки, висловлені в цій статті, належать виключно автору і не є інвестиційною порадою.
- Переклади статті іншими мовами виконані командою Gate Learn. Якщо не зазначено інше, копіювання, розповсюдження або плагіат перекладених статей заборонені.
Статті на тему

Усе, що вам потрібно знати про кількісну стратегію торгівлі

Що таке Wrapped Ethereum (WETH)?

Що таке Neiro? Все, що вам потрібно знати про NEIROETH у 2025 році

Що таке Об'єднання?

Що таке Ethereum 2.0? Розуміння злиття
